
Client Overview
A Century-Old Leader in Automotive Information Solutions
Our client is an American company with over 100 years of history in the automotive information industry. A pioneer in repair information, shop management software, and marketing tools, they serve hundreds of thousands of automotive and commercial truck repair professionals across North America. Their platforms are mission-critical: any data disruption directly impacts technicians' ability to diagnose and repair vehicles.
The Business Challenge
A 100-Year Data Estate, 4,500 Plus Tables, and Zero Tolerance for Downtime
The client's strategic roadmap required migrating from complex, highly normalized on-premises SQL Server systems to Microsoft Dynamics 365 as the new system of record while maintaining full operational continuity for active users.
Our Solution
A Bidirectional Synchronization Engine on Microsoft Fabric, Built for Massive Scale
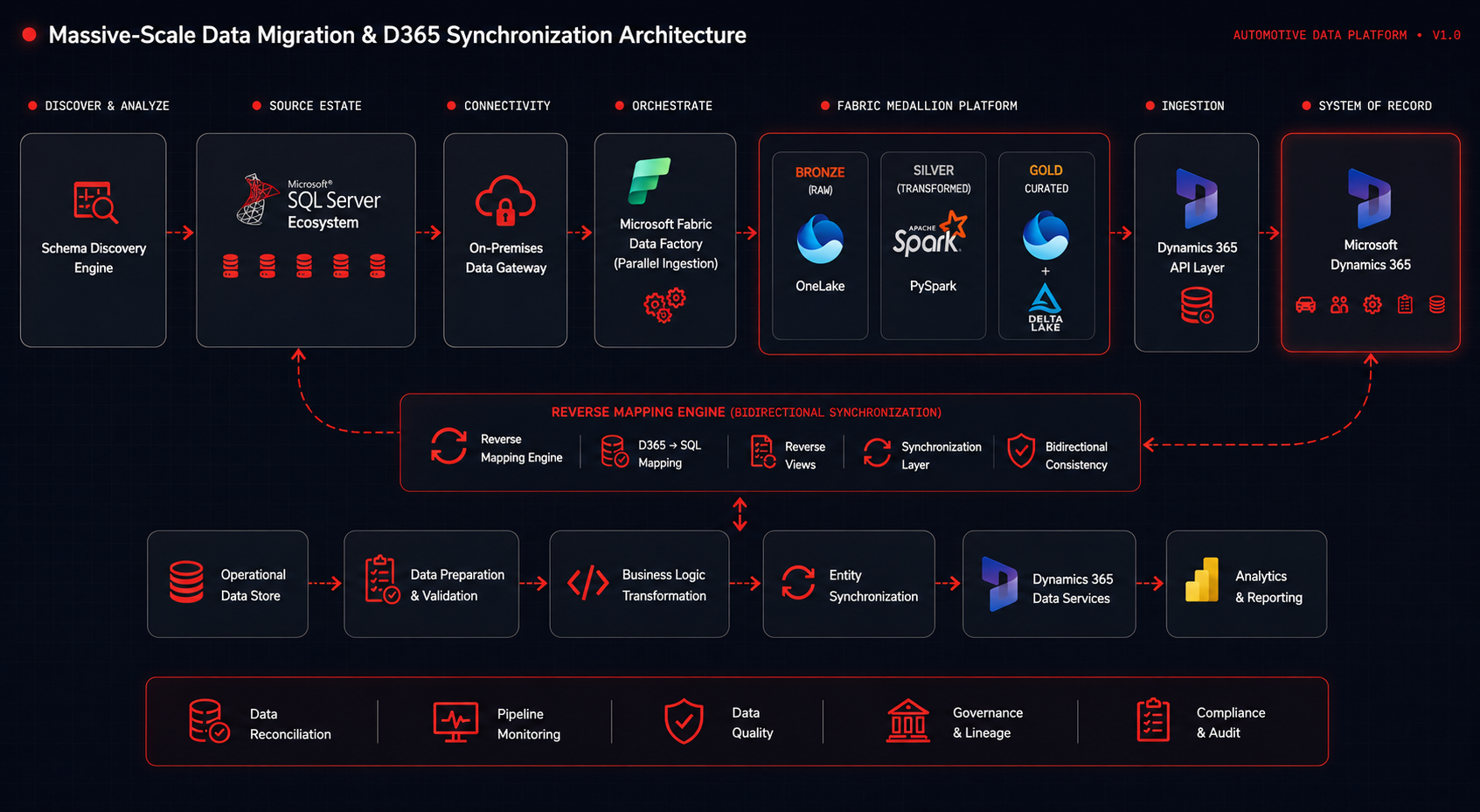
OptroniX delivered a multi-phase integration architecture handling both the initial bulk migration and the ongoing bidirectional synchronization between SQL Server and D365.
Source Analysis and Schema Mapping
Automated schema discovery cataloged all 4,500 plus tables, identified primary and foreign key relationships, classified data domains, and produced a full entity relationship map. This formed the foundation for all subsequent transformation logic across the entire migration.
Parallel Bulk Ingestion into OneLake
Fabric Data Factory pipelines were optimized for parallel execution, extracting multiple table groups simultaneously while carefully managing SQL Server resource consumption to avoid impacting production workloads throughout the migration window.
JSON Transformation for D365
PySpark notebooks converted relational SQL records into JSON documents conforming to D365 entity schemas. This covered field-level type mapping, null handling, default value application, and flattening nested relational structures into D365-compatible payloads for hundreds of entity types.
ADLS Staging Buffer Layer
Azure Data Lake Storage Gen2 was integrated as a high-throughput staging layer for large payload batches before D365 ingestion. This decoupled ingestion pipeline speed from D365 API rate limits, ensuring no data loss under peak load conditions.
D365 Ingestion and Reverse Mapping
JSON payloads were ingested into D365 via its API layer. Views were simultaneously created in Fabric to map D365 entity data back to on-premises SQL Server table structures, enabling full bidirectional consistency throughout the parallel-run period.
Automated Reconciliation and Monitoring
Automated checks compared record counts and key field checksums across SQL Server, OneLake, and D365, flagging any discrepancies for engineering review. A monitoring dashboard provided real-time throughput, failure rates, and D365 sync latency visibility at all times.
Technical Architecture
Massive-Scale Data Migration and D365 Synchronization Architecture
Full end-to-end pipeline: from schema discovery and parallel ingestion through JSON transformation, ADLS staging, D365 ingestion, and bidirectional reverse mapping back to on-premises systems.
Results and Business Impact
Industry-Leading Scale. Zero Disruption.
"The scale of what OptroniX handled, 4,500 tables, full JSON transformation, D365 sync running parallel to our production systems, is something most integration teams would have balked at. They delivered without a single production incident."
Key Takeaways
What This Project Taught Us
Schema Discovery Must Come Before Design
At 4,500 plus table scale, automated schema cataloging is not optional. It is the prerequisite for every design decision that follows. Skipping it guarantees rework mid-migration at the worst possible time.
Parallel Execution Is the Only Path at This Scale
Single-threaded pipeline design would have made this project technically infeasible within any realistic timeline. Microsoft Fabric's native parallelism was a core architectural advantage that made the delivery possible.
ADLS as a Buffer Protects D365 from Overload
D365 API rate limits are a real constraint at high volume. ADLS Gen2 staging decoupled ingestion pipeline speed from D365's consumption capacity, preventing throttling errors from derailing the entire migration.
Design for Bidirectionality from Day One
Retrofitting reverse views and sync mappings after the initial migration is significantly more expensive than building for bidirectionality from the start. The parallel-run requirement must inform the architecture before a single pipeline is built.