Enterprise Data Modernization Case Study
How a Global Hospitality Enterprise Modernized 150+ SQL Server Tables with Microsoft Fabric
How a global hospitality enterprise migrated 150+ SQL Server tables into Microsoft Fabric using automated ingestion pipelines, PySpark transformations, and Medallion Architecture.
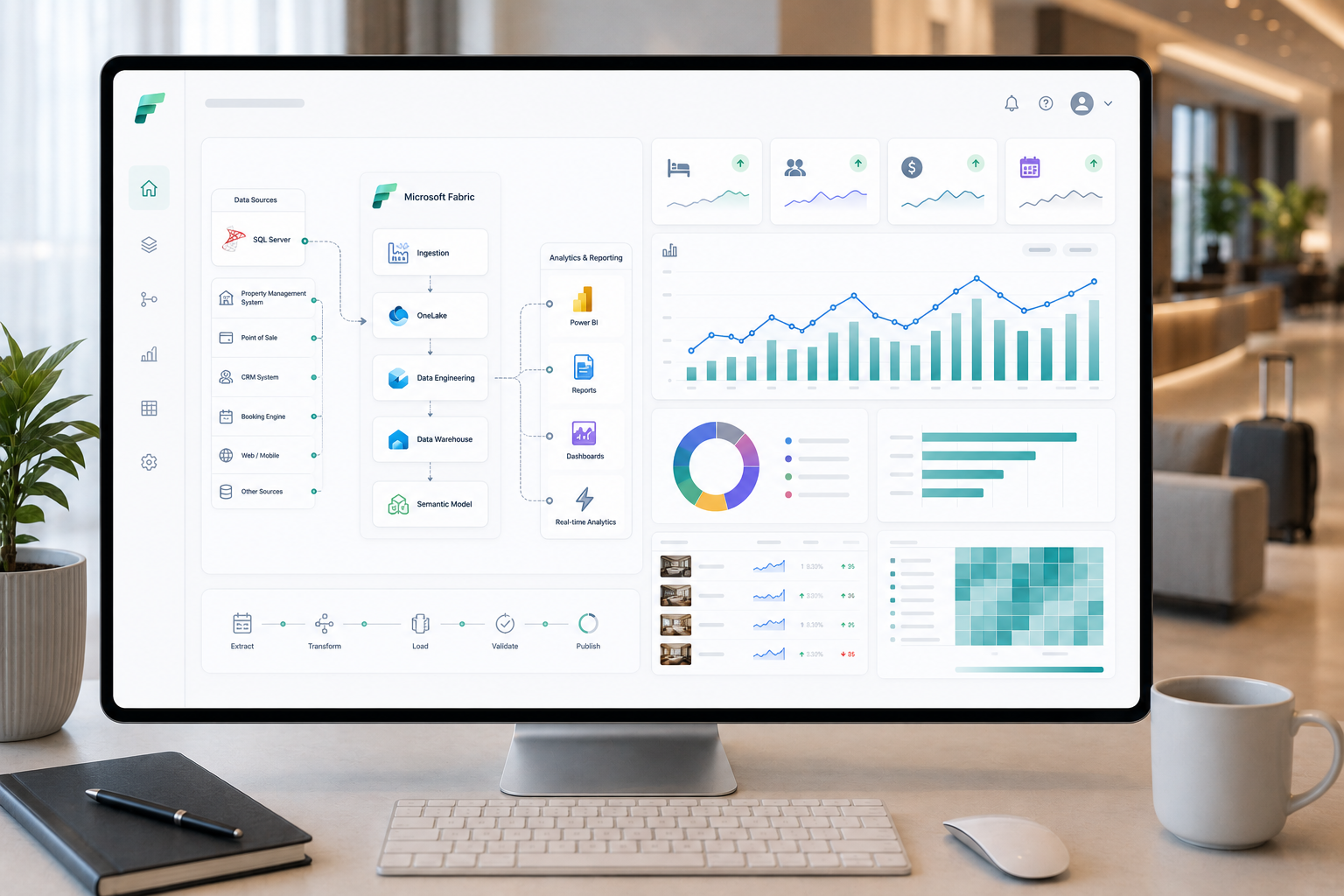
The Situation
A global hospitality and club management enterprise was facing increasing pressure from fragmented reporting systems, growing operational datasets, and aging on-premises infrastructure.
Operating across hundreds of international locations, the organization relied heavily on SQL Server reporting environments that struggled to scale with increasing analytical workloads.
Leadership needed a centralized analytics platform capable of supporting governance, scalability, and modern reporting requirements without disrupting operational systems.
Existing Environment
| Component | Technology |
|---|---|
| Operational Database | SQL Server |
| ETL Processing | Legacy ETL Workflows |
| Reporting Layer | Traditional BI Reports |
| Data Processing | Manual Transformations |
Challenges Identified
Large-Scale Migration
The migration involved more than 150 tables and millions of records that needed to be transferred while preserving schema consistency and transformation logic.
Transformation Complexity
Transformation rules existed across disconnected reporting systems, resulting in duplicate logic and inconsistent outputs.
Performance Limitations
Existing reporting pipelines struggled with long refresh cycles and increased load on operational databases.
Lack of Structured Layers
Raw operational data and business-ready reporting datasets existed together without clear architectural separation.
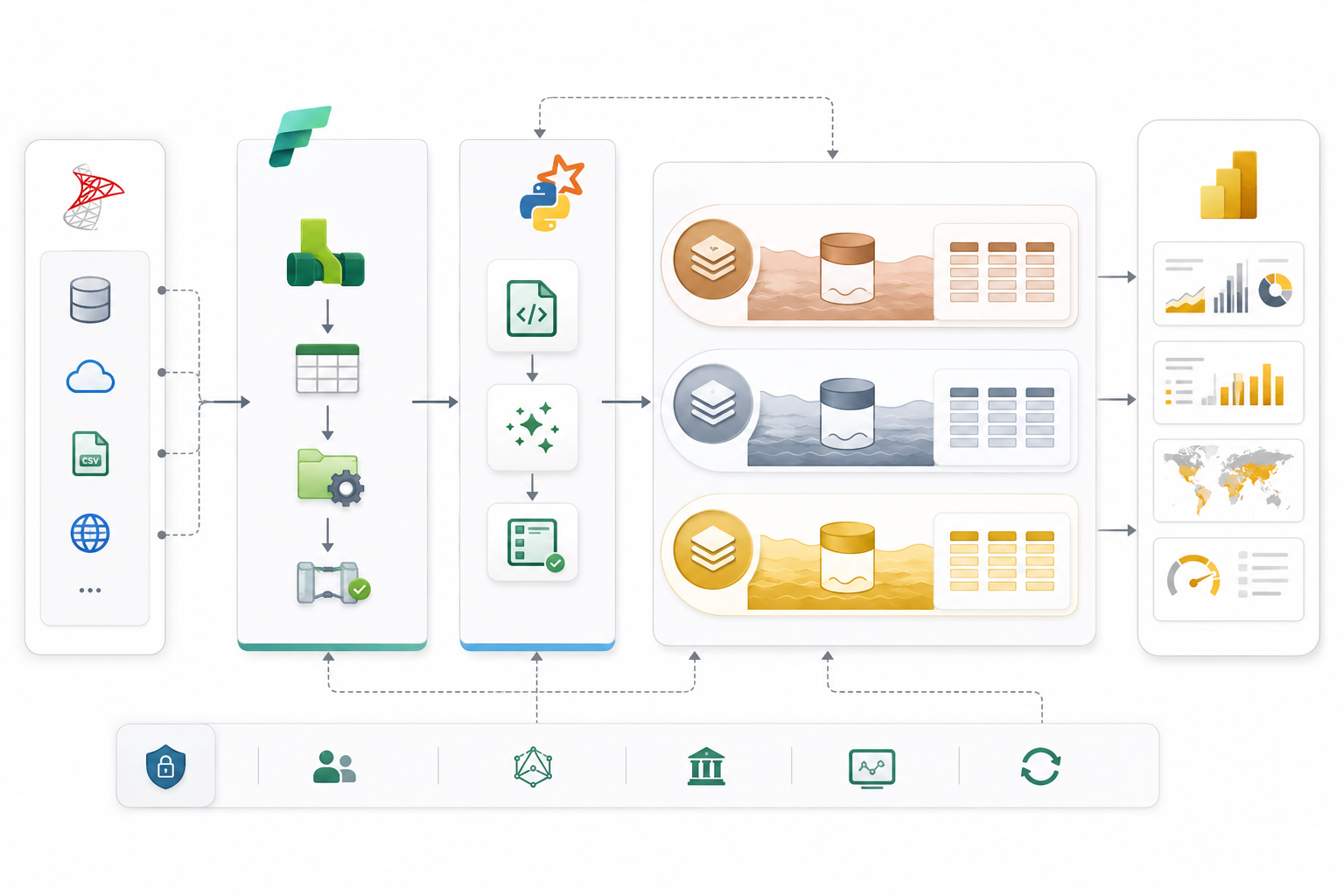
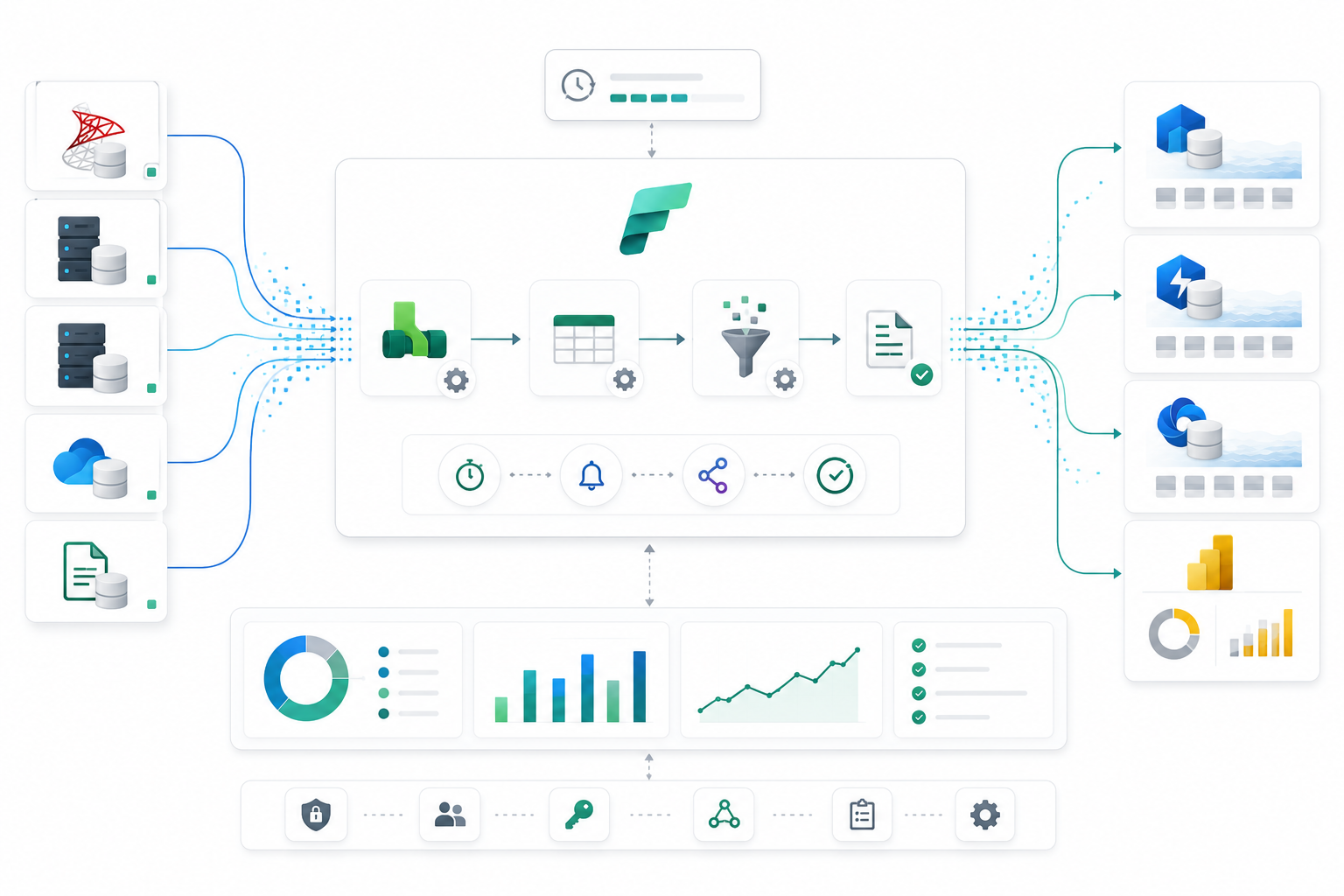
Data Ingestion with Fabric Data Factory
Automated ingestion pipelines were built using Microsoft Fabric Data Factory to move large volumes of data from SQL Server environments into Microsoft Fabric.
These pipelines supported incremental loading, automation, and scalable ingestion workflows while minimizing manual operational effort.
- Incremental loading support
- Automated pipeline orchestration
- Reduced manual intervention
- Scalable migration workflows
Transformation Layer with PySpark
Fabric Notebooks and PySpark were used to centralize transformation logic and standardize processing across the analytics environment.
Transformation workflows handled cleansing, schema alignment, standardization, deduplication, and business-rule implementation.
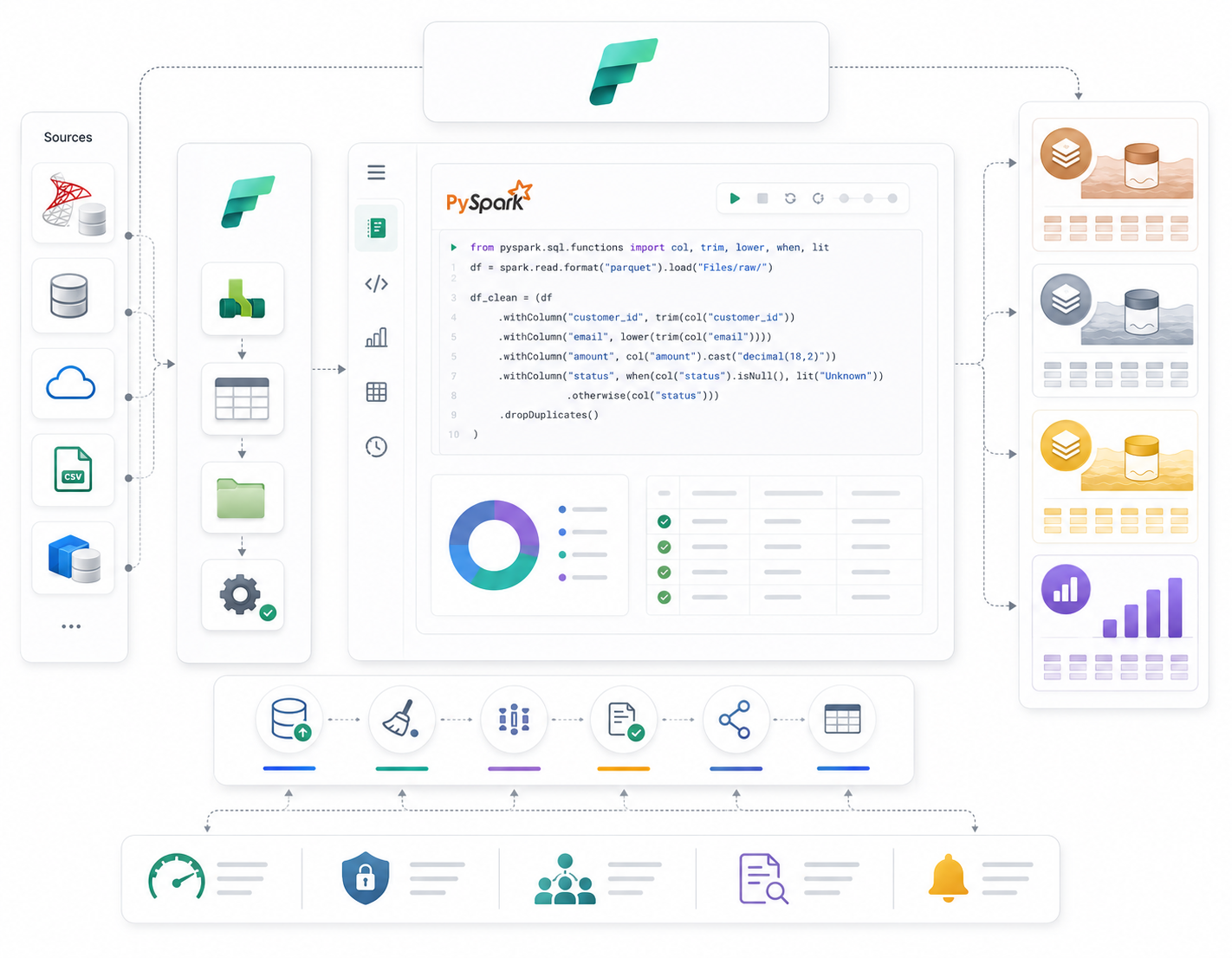
Implementing Medallion Architecture
Bronze Layer
Raw ingested data stored exactly as received from source systems for auditing and recovery purposes.
Silver Layer
Cleansed and validated operational datasets standardized for downstream analytics processing.
Gold Layer
Business-ready analytical datasets optimized for reporting, dashboards, and executive analytics.
Business Impact
Centralized Analytics
Established a unified cloud-based reporting and analytics environment.
Improved Governance
Standardized transformation layers improved data quality and governance visibility.
Performance Optimization
Reduced reporting bottlenecks and improved downstream analytical performance.
Scalable Foundation
Built a future-ready platform capable of supporting enterprise analytics growth.
Technologies Used
Final Outcome
The organization successfully transitioned from fragmented legacy reporting systems to a centralized Microsoft Fabric analytics platform capable of supporting scalable reporting, governance, and future analytical workloads.