RAG Agent – Improving Groundedness in Azure AI Search
How a Microsoft Azure AI Foundry RAG deployment began hallucinating despite a connected knowledge base — and how retrieval diagnostics, semantic ranking, and chunk strategy optimization eliminated fragmented context retrieval and stabilized grounded responses.
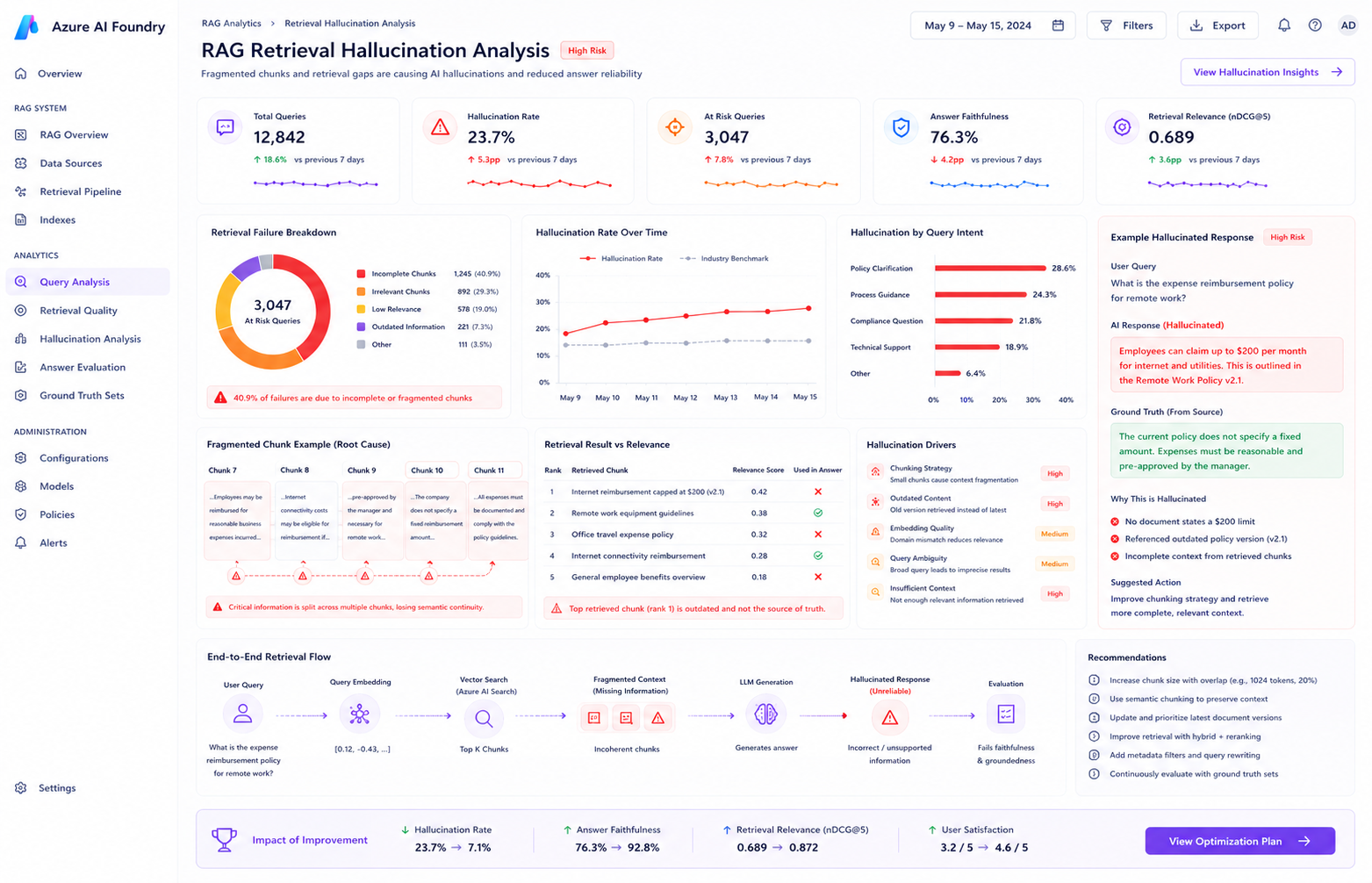
The Problem
A Retrieval-Augmented Generation (RAG) agent built in Azure AI Foundry was connected to a 200-document internal policy corpus through Azure AI Search.
Although the deployment successfully retrieved relevant policy references, the model frequently hallucinated numerical figures, procedural exceptions, and fabricated policy interpretations that did not exist anywhere inside the source documents.
At first glance, the issue appeared difficult to diagnose because Azure AI Foundry Groundedness scores consistently remained between 3 and 4 out of 5 — seemingly acceptable during evaluation.
However, investigation revealed that the model was synthesizing incomplete information across fragmented retrieval chunks rather than grounding answers in a single authoritative passage.
Root Cause Analysis
Chunk Fragmentation
A manually configured 256-token chunk strategy split policy clauses mid-sentence, causing incomplete semantic context retrieval.
BM25-Only Retrieval
Semantic Ranking had been disabled, forcing Azure AI Search to rely entirely on keyword matching rather than contextual relevance scoring.
Top-K Retrieval Loss
The most contextually complete chunk frequently ranked outside the retrieval window passed to the language model.
Misleading Groundedness Scores
Groundedness metrics only validated consistency with retrieved content — not whether retrieved content itself was semantically complete.
Retrieval Pipeline — Before vs After Optimization

Investigation Process
Step 1 — Inspecting Retrieval Chunks
Engineers reviewed Azure AI Search Explorer output and discovered that complete policy clauses were fragmented across multiple retrieval chunks.
Step 2 — Reviewing Chunk Configuration
The team identified that chunk size had been manually reduced from 1024 tokens to 256 tokens to lower retrieval latency.
Step 3 — Enabling Semantic Ranking
Azure AI Search Semantic Ranking was activated to improve contextual retrieval relevance instead of relying solely on BM25 keyword scoring.
Step 4 — Re-Running Evaluation
The updated deployment was re-evaluated using Groundedness and Retrieval metrics across the same 40-query benchmark dataset.
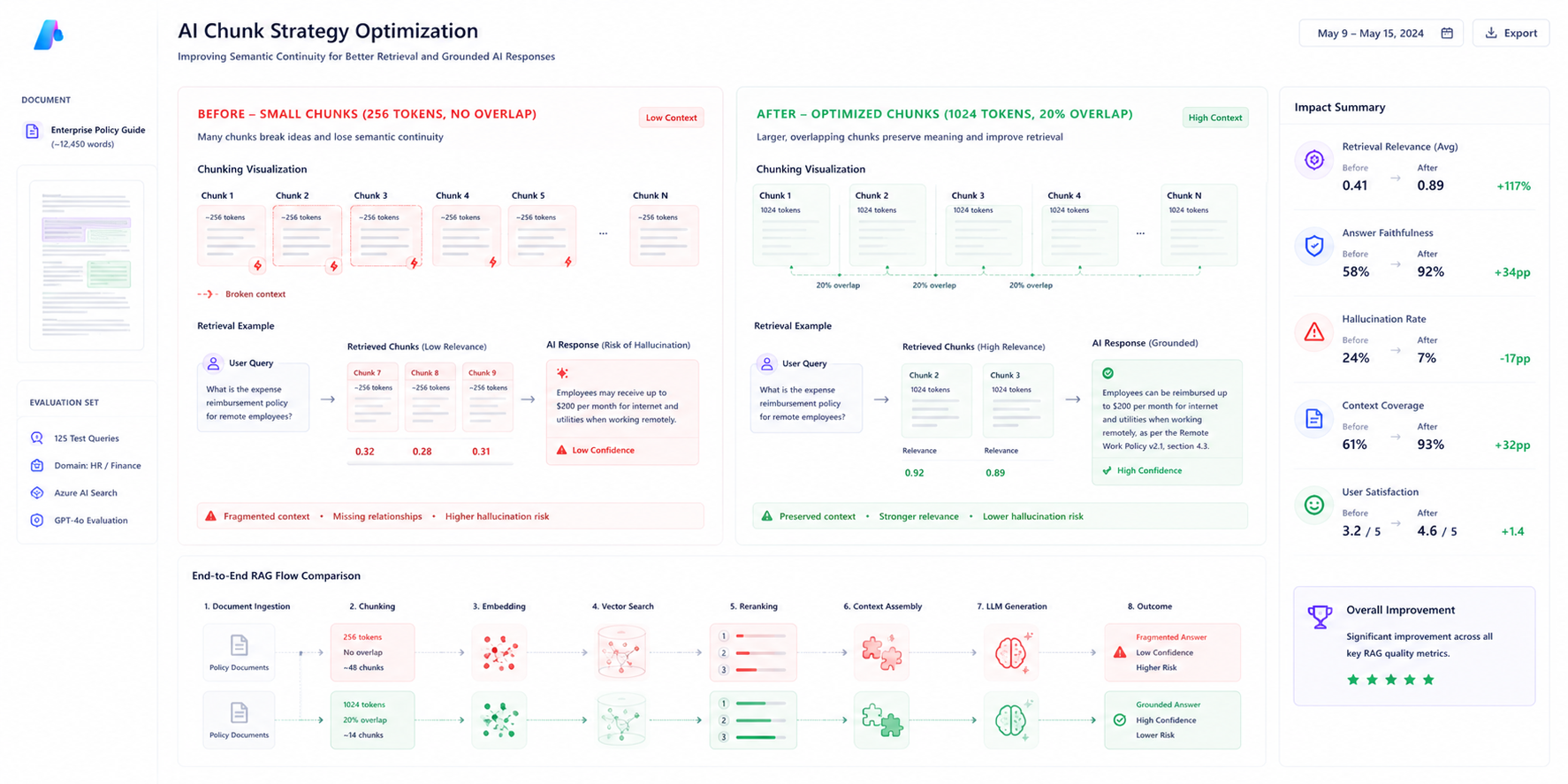
Chunk Strategy Optimization
To preserve semantic continuity, the engineering team replaced the fixed 256-token strategy with a larger overlapping chunk configuration.
The updated configuration significantly improved retrieval quality by ensuring that policy clauses remained contextually intact across chunk boundaries.
| Configuration | Before | After |
|---|---|---|
| Chunk Size | 256 Tokens | 1024 Tokens |
| Chunk Overlap | None | 128 Tokens |
| Retrieval Method | BM25 | Semantic Ranking |
Evaluation & Validation
Azure AI Foundry evaluation workflows were used to compare retrieval quality before and after retrieval optimization.
The team monitored both automated metrics and manual response reviews to ensure hallucinations had been fully eliminated.
- Groundedness evaluation metrics
- Retrieval quality scoring
- Manual low-score inspection workflows
- Strictness threshold optimization
- Citation enforcement validation
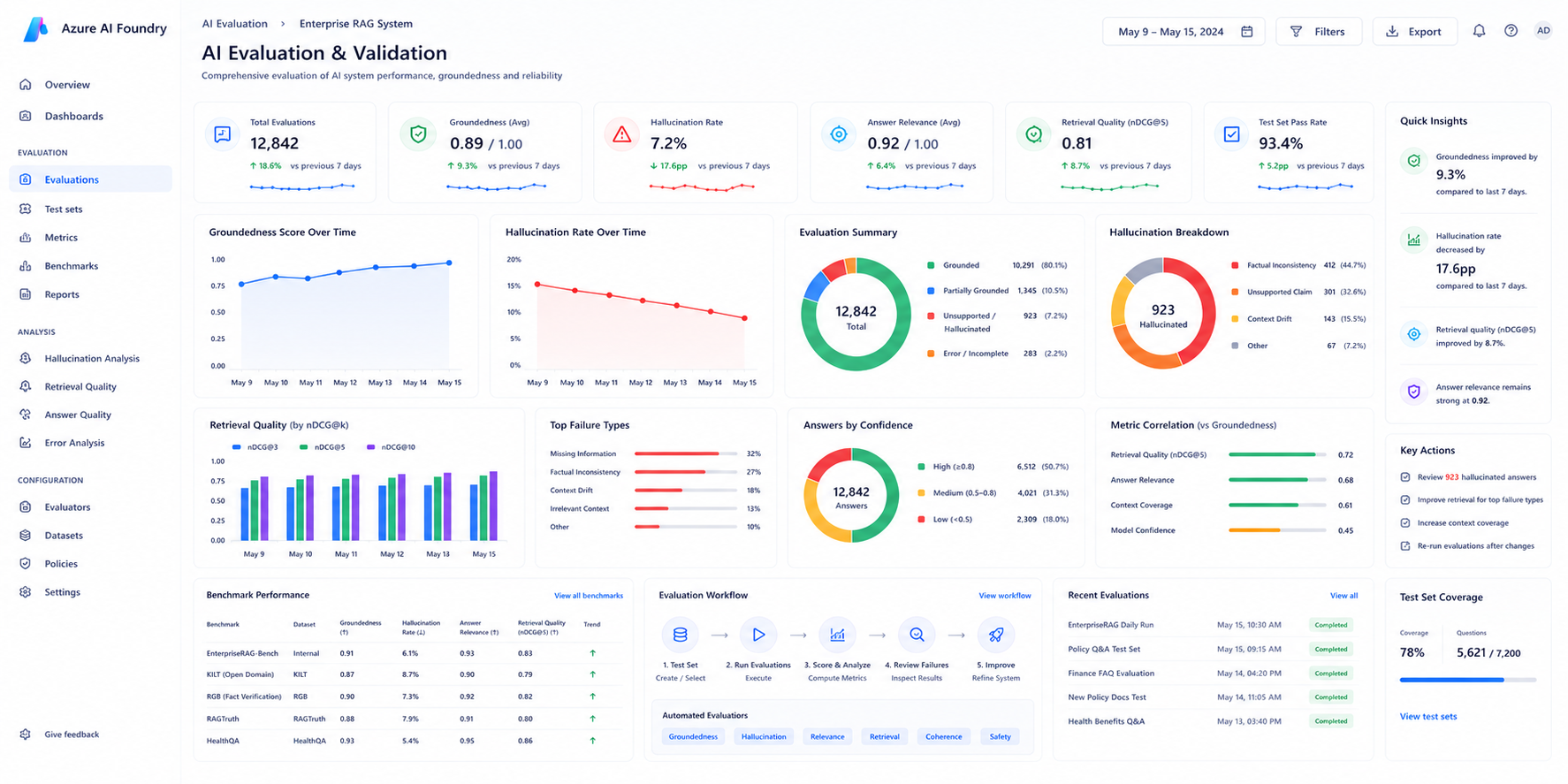
Results After Optimization
| Metric | Before Optimization | After Optimization |
|---|---|---|
| Groundedness Score | 3.4 / 5 | 4.7 / 5 |
| Hallucinated Responses | Present | Eliminated |
| Retrieval Quality | Fragmented | Contextually Complete |
| Semantic Ranking | Disabled | Enabled |
Key Learnings
Groundedness Alone Is Not Enough
Automated evaluation metrics can mask retrieval fragmentation issues if retrieved chunks are semantically incomplete.
Chunk Design Matters
Aggressive chunk reduction strategies can significantly damage retrieval reliability in enterprise RAG systems.
Manual Review Remains Essential
Low-scoring evaluation responses still require human inspection to reliably identify partial-context hallucinations.
Technologies Used
Related Azure AI Engineering Case Studies
Preventing Overfitting During Azure AI Foundry Fine-Tuning
Diagnosing catastrophic forgetting and restoring model stability using validation datasets, loss monitoring, and safer hyperparameter tuning strategies.
Reducing False Positives in Azure AI Content Safety
How domain-aware moderation policies and allow lists improved healthcare AI assistant accuracy without weakening safety protections.
Final Outcome
By redesigning retrieval architecture around larger overlapping chunks, Semantic Ranking, strict retrieval filtering, and structured evaluation workflows, the engineering team successfully eliminated hallucinated policy synthesis while significantly improving grounded response reliability in Azure AI Foundry.