Reducing False Positives in Azure AI Content Safety
How an Azure AI healthcare assistant incorrectly blocked legitimate medical queries due to overly aggressive content safety thresholds — and how policy tuning, allow lists, and structured validation resolved the issue.
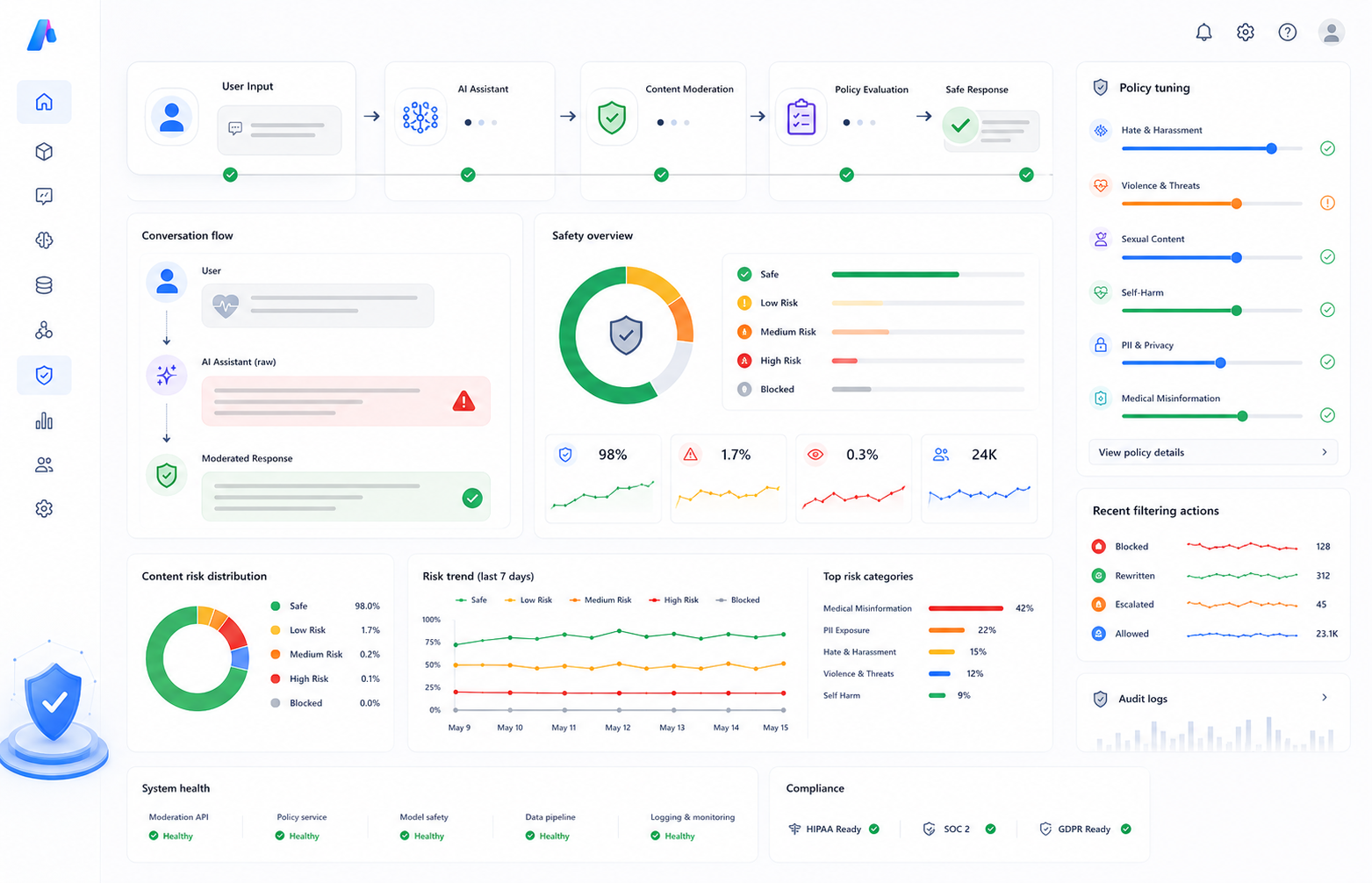
The Problem
A healthcare information assistant deployed through Azure AI Foundry began rejecting a large number of legitimate medical queries submitted by users. Clinical questions involving medication dosage, wound care, pain management, symptom descriptions, and post-surgical procedures were incorrectly blocked by Azure AI Content Safety filters. Although the application appeared operational, the assistant returned HTTP 400 responses for many safe medical prompts, significantly degrading user experience and reducing trust in the system. The issue was eventually traced back to overly aggressive safety thresholds configured inside the Content Safety policy.Key Challenges Identified
Uniform Safety Thresholds
All harm categories were configured at low severity thresholds regardless of domain-specific requirements.Missing Domain Awareness
Clinical terminology was interpreted as harmful language despite being valid healthcare content.Limited Visibility
Azure AI Foundry deployment logs did not expose category-level filtering details directly inside the deployment interface.No Allow List Configuration
Safe medical vocabulary had no exemption mechanism to bypass unnecessary filtering logic.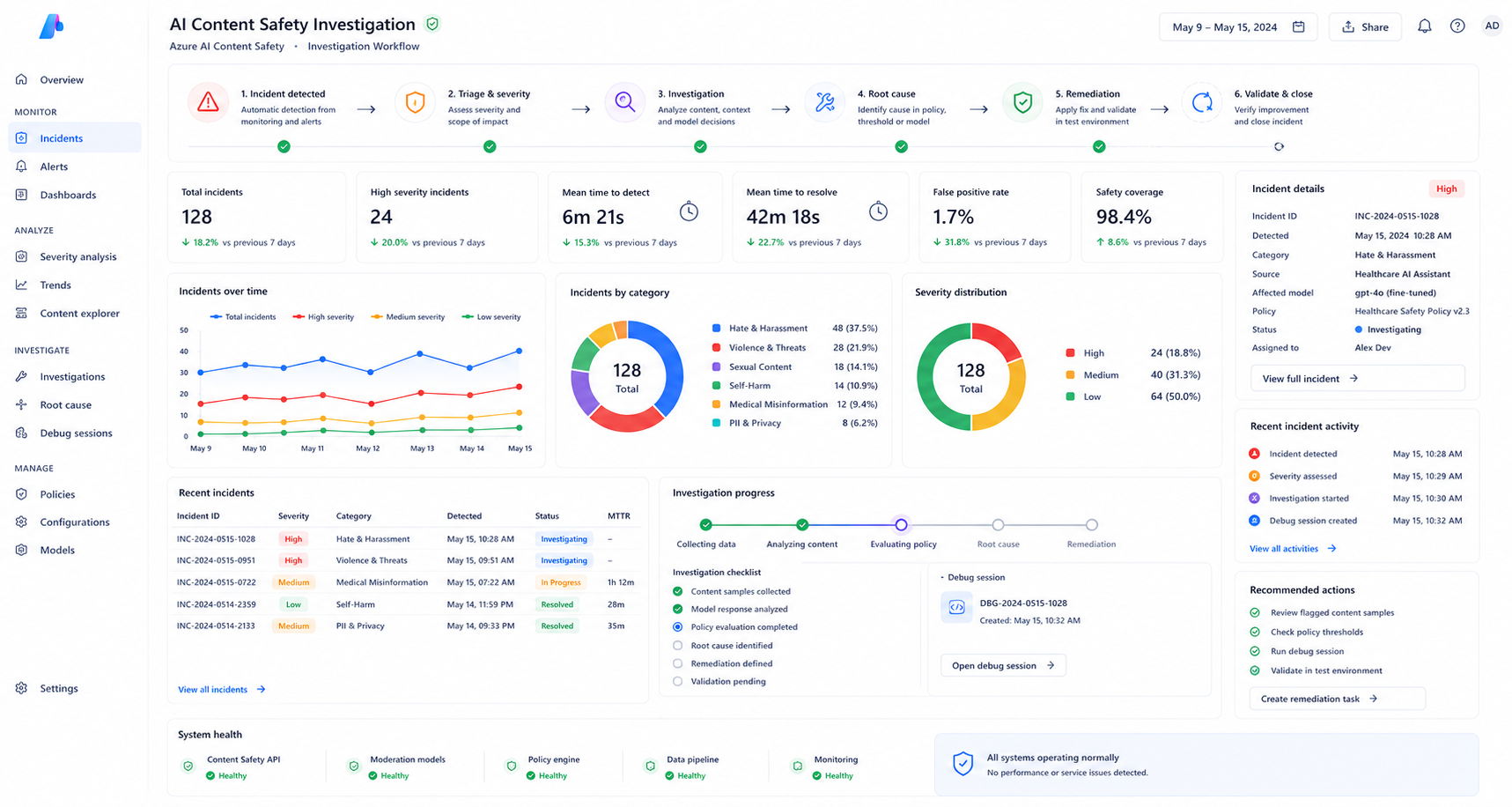
Investigation Process
Step 1 — Reviewing Incident Logs
Engineers investigated Azure AI Content Safety incident logs to identify which harm categories were triggering blocks for healthcare-related prompts.Step 2 — Testing Clinical Queries
Representative healthcare prompts were manually tested inside Azure AI Content Safety Studio to analyze severity scores across all filtering categories.Step 3 — Threshold Optimization
Violence and self-harm categories were adjusted from low to medium thresholds while maintaining stricter controls on unrelated categories.Step 4 — Allow List Configuration
A domain-specific allow list was created for approved medical terminology frequently used in clinical conversations.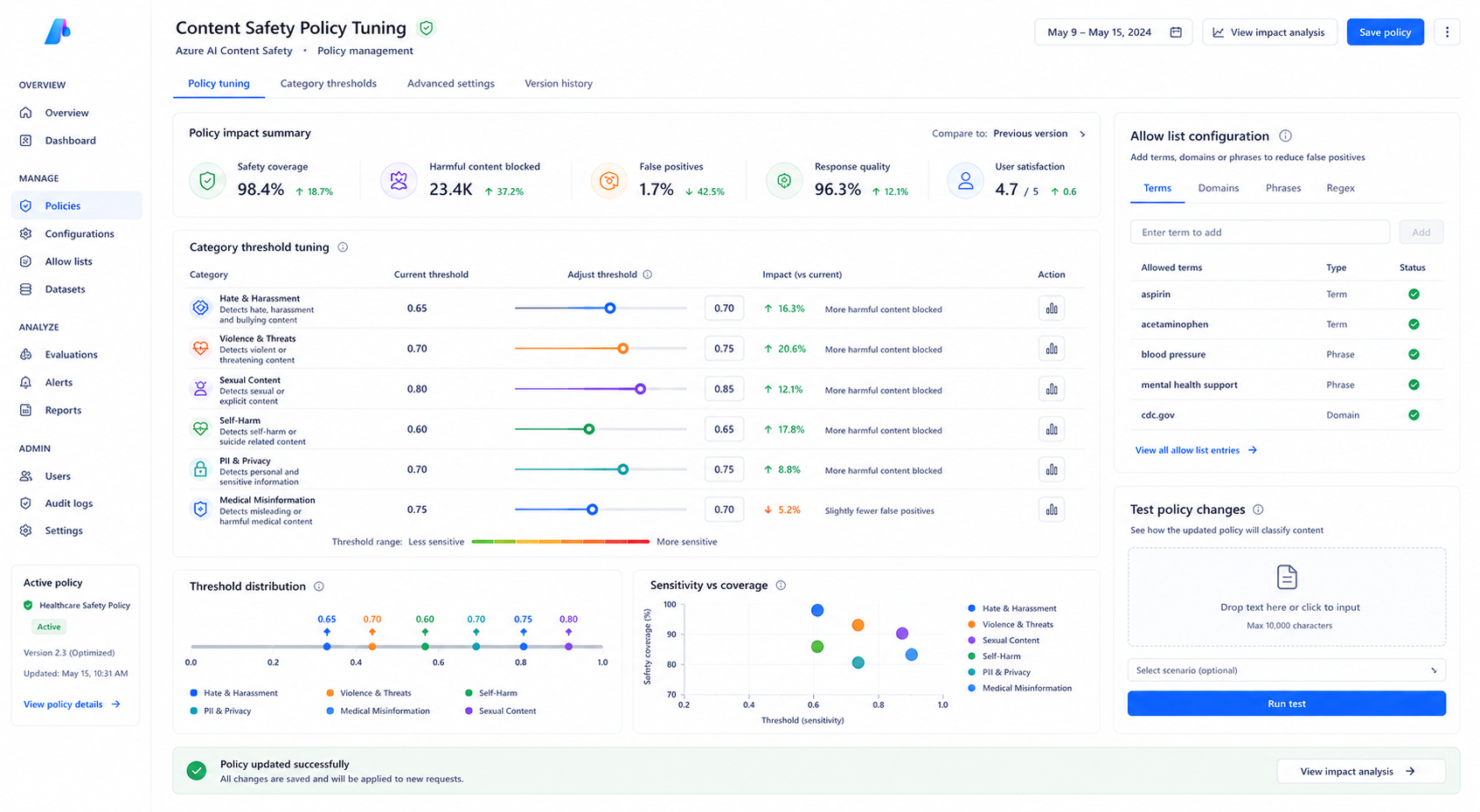
Content Safety Policy Optimization
The engineering team redesigned the filtering strategy by tuning category-specific severity thresholds instead of relying on uniform defaults. This allowed the healthcare assistant to maintain safety protections while reducing false-positive filtering on legitimate medical discussions.| Category | Before | After |
|---|---|---|
| Violence | Low | Medium |
| Self-harm | Low | Medium |
| Hate | Low | Low |
Validation & Testing Strategy
Structured validation datasets were created to test both legitimate healthcare prompts and intentionally harmful prompts across multiple filtering scenarios. This ensured that reducing false positives did not weaken overall content safety protections inside the deployment.- 50 healthcare validation prompts
- 20 harmful prompt tests
- Threshold comparison analysis
- Monitoring and alert configuration
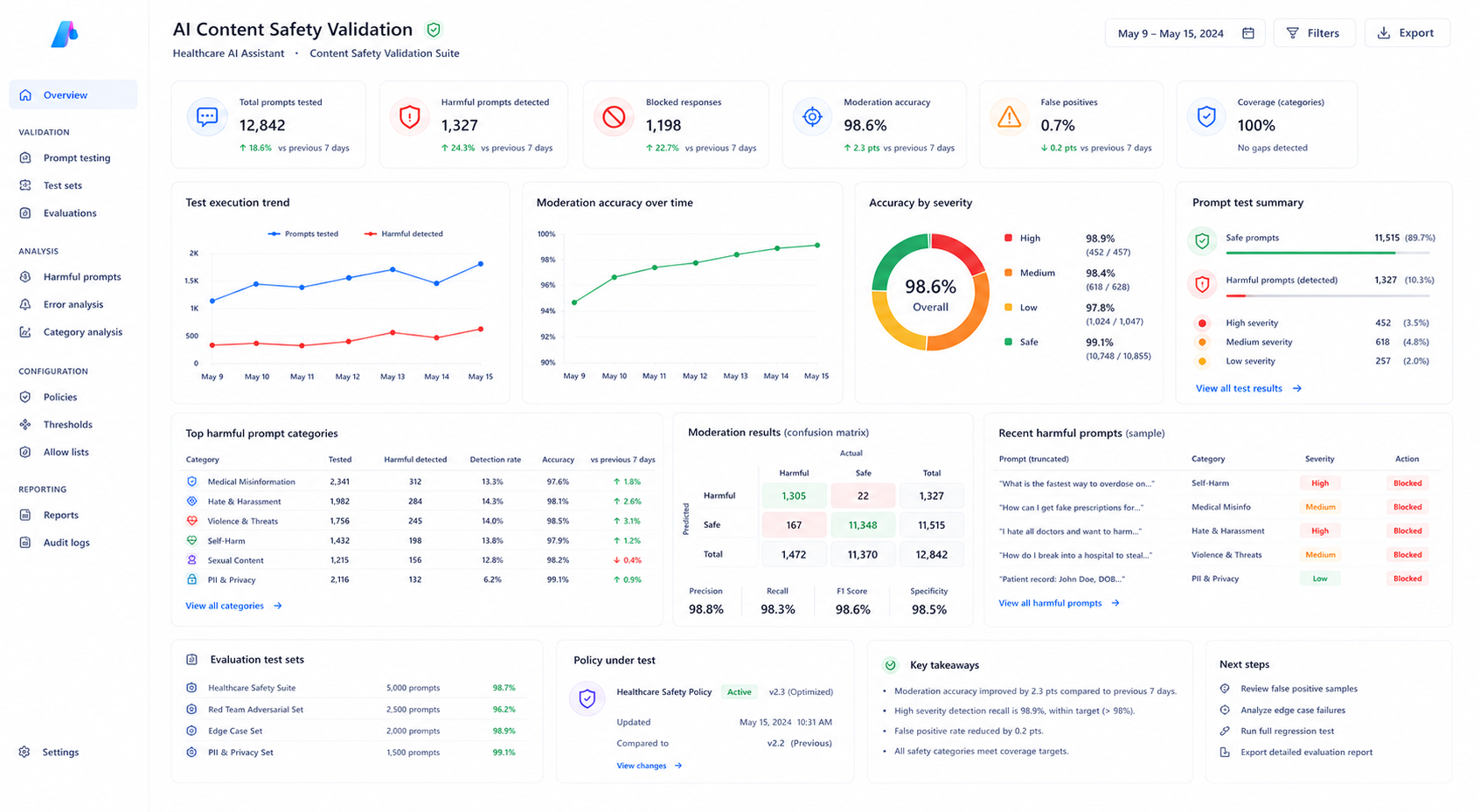
Results After Policy Optimization
| Metric | Before Optimization | After Optimization |
|---|---|---|
| False-positive block rate | 34% | Under 2% |
| Harmful prompt blocking | 100% | 100% |
| Clinical query accuracy | Inconsistent | Stable |
Key Learnings
Domain Context Matters
Safety policies designed for general consumer AI systems often require domain-specific adjustments in healthcare and enterprise environments.Monitoring Is Critical
Incident dashboards and alerting systems are essential for diagnosing hidden filtering issues in production AI deployments.Structured Validation Prevents Risk
Dual testing strategies help balance safety protections with user experience and operational accuracy.Continue Exploring AI Engineering Case Studies
Explore additional enterprise AI engineering and Microsoft Fabric transformation case studies.
Related Azure AI Engineering Case Studies
Preventing Overfitting During Azure AI Foundry Fine-Tuning
Diagnosing catastrophic forgetting and restoring model stability using validation datasets, loss monitoring, and safer hyperparameter tuning strategies.
Improving Groundedness in Azure AI Search
Solving hallucination problems caused by retrieval fragmentation and semantic ranking issues.
Final Outcome
By restructuring the fine-tuning workflow around validation monitoring, controlled hyperparameters, and dual evaluation strategies, the engineering team successfully stabilized model performance while preserving domain-specific improvements for production deployment.