Azure AI Foundry Case Study
Preventing Fine-Tuning Overfitting in Azure AI Foundry
How an Azure AI Foundry fine-tuning deployment began overfitting on a small dataset — and how hyperparameter optimization, validation monitoring, and structured evaluation stabilized the model before production deployment.
68 JSONL Training Examples
GPT-4o-mini Fine-Tuning
Azure AI Foundry
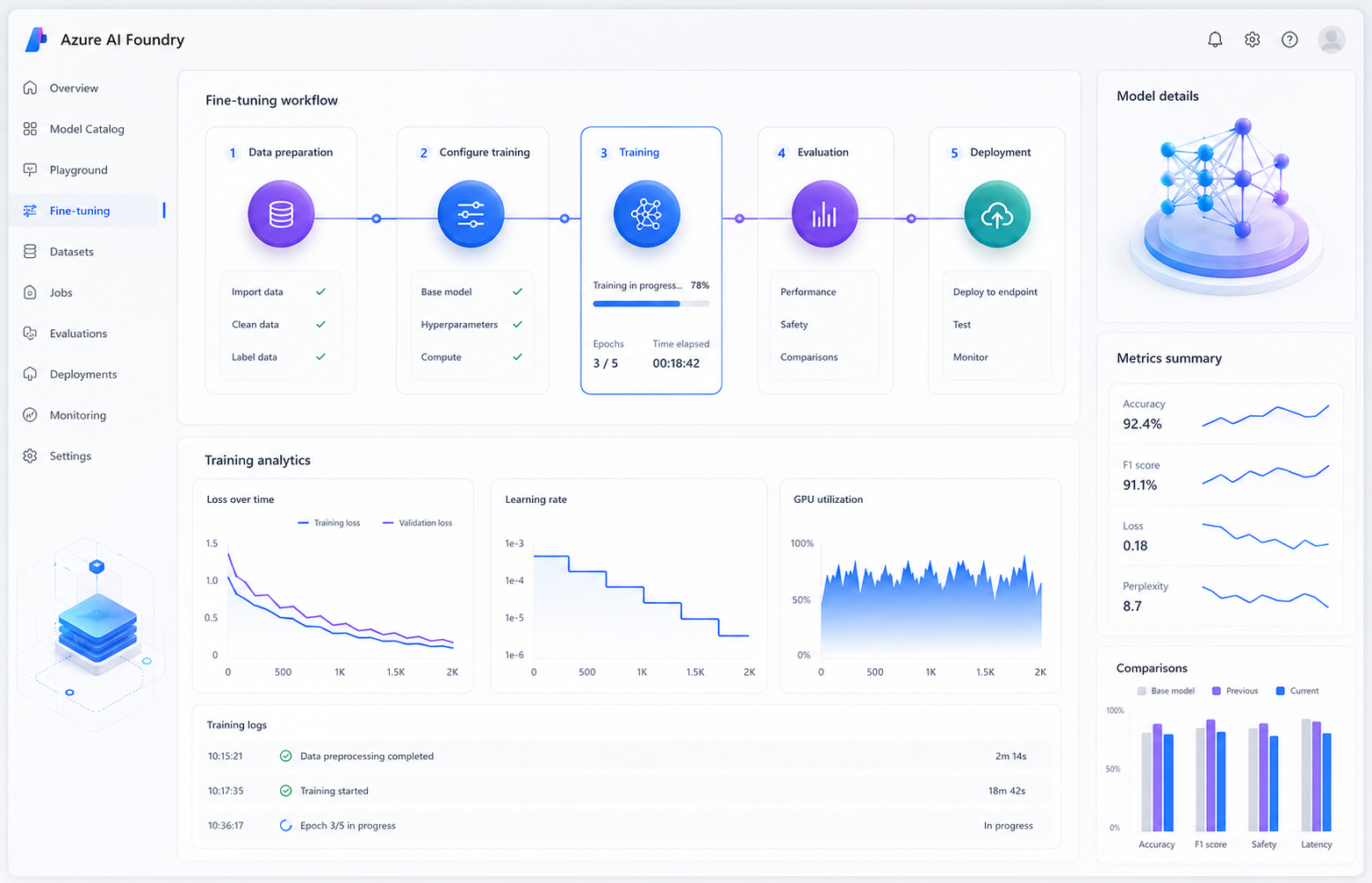
The Problem
A developer fine-tuned GPT-4o-mini inside Azure AI Foundry using a small domain-specific dataset consisting of 68 JSONL examples designed for technical support responses. Initially, the model appeared successful. Domain-specific queries improved noticeably, and the training process completed without errors or warnings inside the Azure AI Foundry interface. However, after deployment, broader model behavior began deteriorating. General reasoning quality declined, response formatting became inconsistent, and instruction-following capabilities weakened significantly. Although training loss appeared healthy, the model had overfit heavily to the training distribution.Why the Failure Happened
Excessive Training Epochs
The default epoch configuration generated far too many gradient updates for such a small dataset.No Validation Dataset
Without a validation split, the platform could not surface validation loss divergence during training.Learning Rate Too Aggressive
Default learning-rate values pushed the model too far away from its original pretrained behavior.Missing General Evaluation
The deployment only evaluated domain accuracy and ignored broader reasoning performance.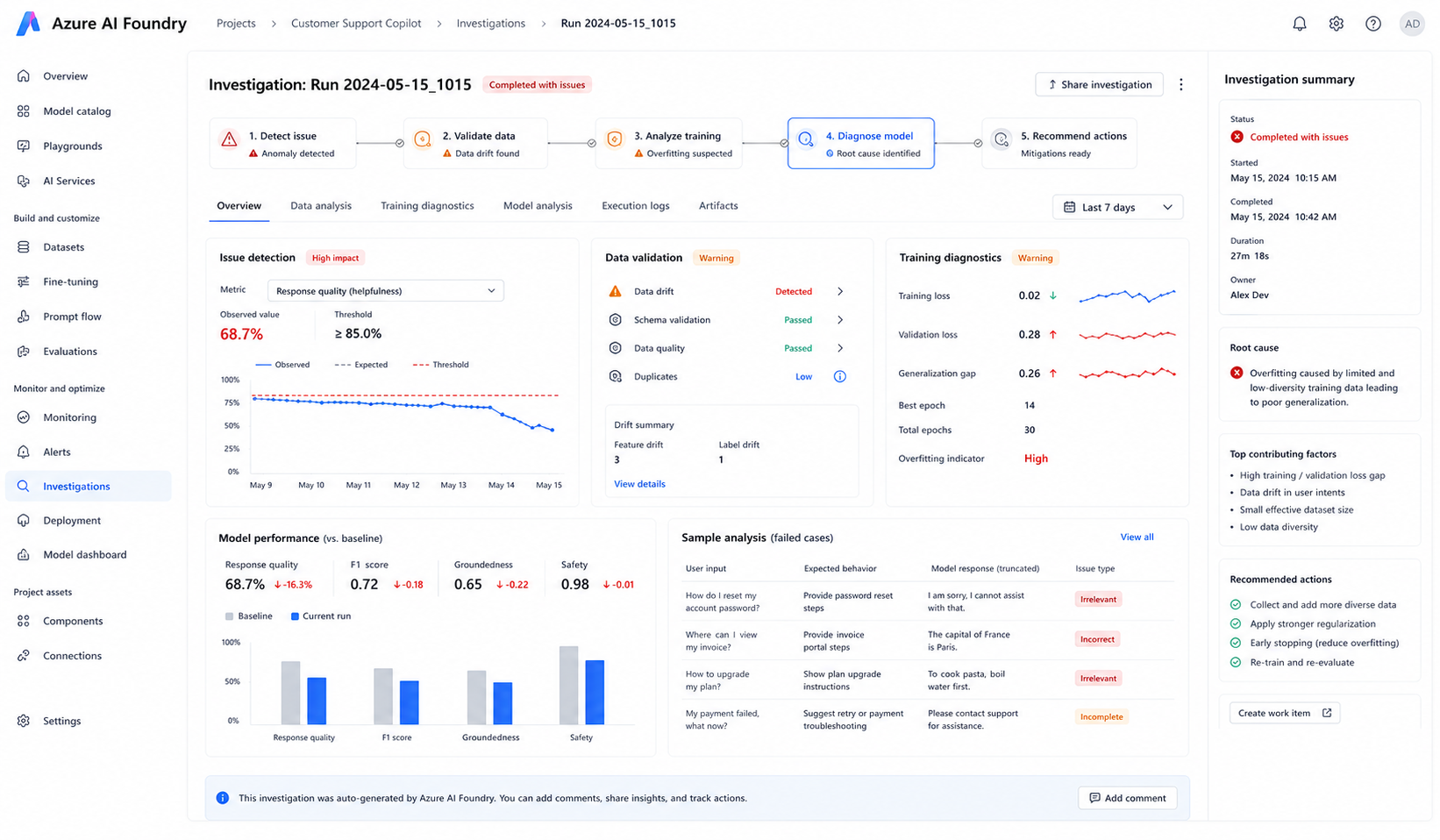
Investigation Process
Step 1 — Reviewing Training Parameters
The engineering team reviewed the Azure AI Foundry training configuration and identified that 10 epochs on a 68-example dataset produced excessive gradient updates.Step 2 — Introducing Validation Monitoring
A dedicated validation dataset was separated from the training set to activate validation loss tracking inside Azure AI Foundry metrics monitoring.Step 3 — Hyperparameter Optimization
Learning-rate multiplier and epoch counts were significantly reduced to prevent the model from drifting away from the base checkpoint behavior.Step 4 — Dual Evaluation Strategy
Separate evaluation datasets were introduced for domain-specific accuracy and general instruction-following quality.
Hyperparameter Optimization
To stabilize model behavior, the engineering team reduced both the learning-rate multiplier and the number of training epochs. These adjustments preserved the pretrained model’s broader reasoning capabilities while still improving technical support performance.| Parameter | Before | After |
|---|---|---|
| Epochs | 10 | 3 |
| Learning Rate | 1.0 | 0.1 |
Evaluation & Validation Strategy
The team implemented dual evaluation workflows to validate both domain-specific improvements and general reasoning stability. Azure AI Foundry evaluation tools were used to monitor coherence, groundedness, and response consistency across multiple benchmark datasets.- Domain-specific evaluation datasets
- General instruction-following benchmarks
- Validation loss monitoring
- Coherence and groundedness scoring
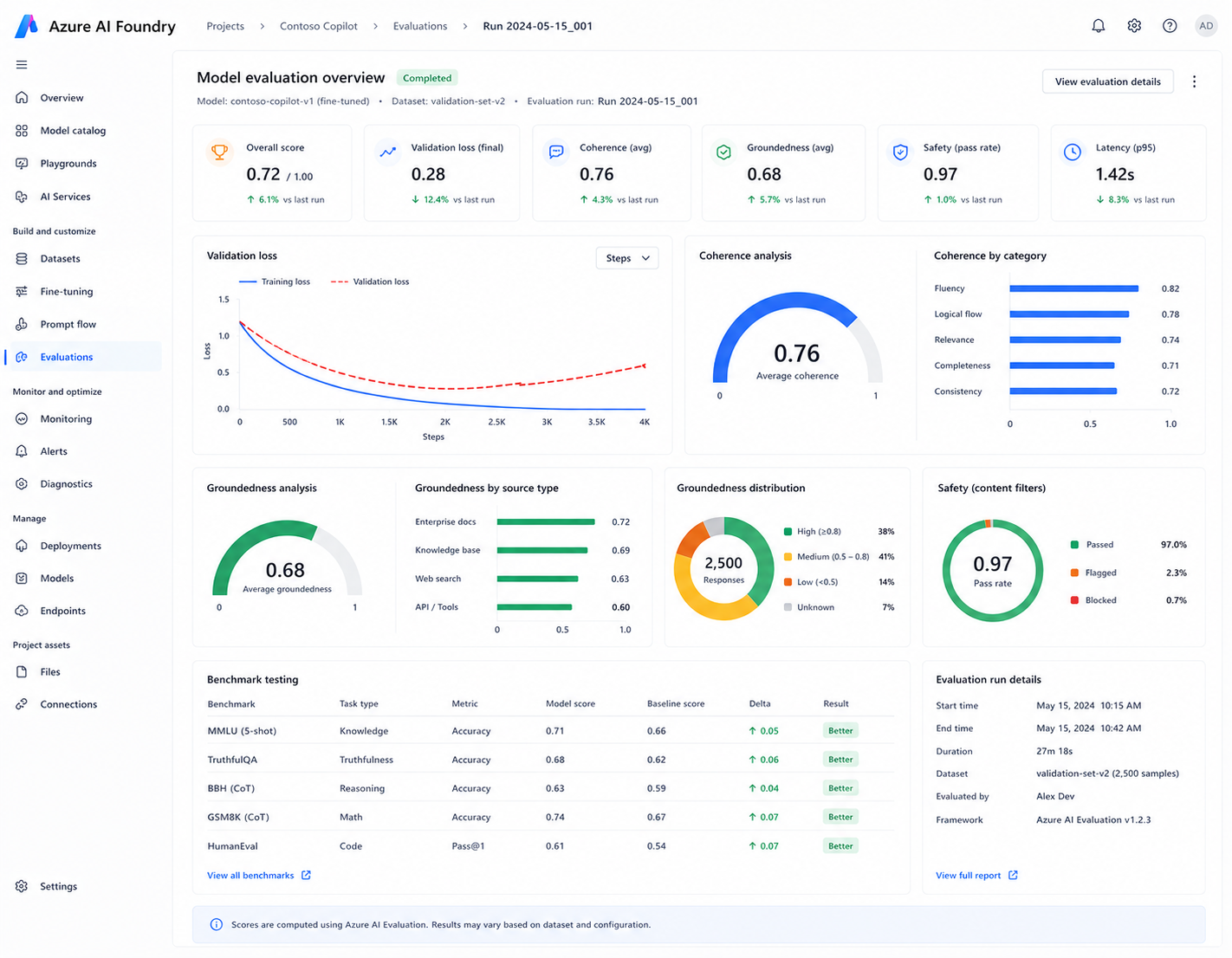
Results After Optimization
| Metric | Before Optimization | After Optimization |
|---|---|---|
| General reasoning quality | Degraded | Stable |
| Validation monitoring | Not configured | Enabled |
| Overfitting risk | High | Controlled |
| Domain accuracy | Improved | Maintained |
Key Learnings
Small Datasets Require Conservative Tuning
Fine-tuning small datasets with aggressive hyperparameters can rapidly degrade base-model behavior.Validation Monitoring Is Critical
Validation loss divergence often becomes the earliest visible sign of overfitting during training.Domain Accuracy Alone Is Not Enough
General reasoning and instruction-following capabilities must always be evaluated alongside domain improvements.Technologies Used
Azure AI Foundry
GPT-4o-mini
Model Evaluation
Validation Monitoring
JSONL Training Dataset
Continue Reading
Related Azure AI Engineering Case Studies
Content Safety
Reducing False Positives in Azure AI Content Safety
How domain-aware moderation policies and allow lists improved healthcare AI assistant accuracy without weakening safety protections.
RAG Evaluation
Improving Groundedness in Azure AI Search
Solving hallucination problems caused by retrieval fragmentation and semantic ranking issues.
Final Outcome
By restructuring the fine-tuning workflow around validation monitoring, controlled hyperparameters, and dual evaluation strategies, the engineering team successfully stabilized model performance while preserving domain-specific improvements for production deployment.